Are positive reviews a quality signal for backlinks?

Several patents have been filed by Google to quantify the opinions and reviews of Internet users from corpus that do not use traditional rating systems. The sentiment analysis then takes on its full meaning: how do we quantify so-called “raw” opinions?
The purpose of this article is not to go into the details of patents but to draw substantial information from them to project the mechanism of weighting sentiments at the level of backlinks: what if the sentiments analysis became an additional rating signal to measure the quality of a backlink?
What do Google’s patents tell us on sentiment analysis?
The patent filed by Hang Cui, Vibhu Mittal and Mayur Datar, on “Comparative Experiences on Sentiment Classification for Online Product Reviews”, introduces the need for sentiment analysis for document classification (in the search results):
A large amount of web content is subjective and reflects people’s opinions. With the rapid growth of the web, more and more Internet users are writing reviews for all types of products and putting them online. It is becoming increasingly common for a consumer to learn how others like or dislike a product before buying it or for a manufacturer to monitor customer feedback on its products to improve customer satisfaction. However, as the number of opinions available for each particular product increases, it becomes increasingly difficult for Internet users to understand and evaluate the dominant opinion on a product. This demonstrates the need for an algorithmic classification of feelings to digest this huge repository of “hidden”criticism.
From there, one can easily imagine that a classification of the backlinks by dominant feeling (ndlr. surrounding the text around the link) would make it possible to measure more precisely the real notoriety of the website (besides the metrics that we already know: citation flow, trust flow, etc.). Opinion as such would then become a discriminating signal in measuring the power of backlink.
However, this hypothesis comes up against multiple difficulties set out in the same patent:
Building feeling classifiers for web-scale processing, with all the problems of pre-processing, spelling and grammar errors, broken HTML… that result, brings about a whole host of other problems. Data sets number hundreds of thousands, sometimes millions, and are neither clean nor consistent. Algorithms must be effective and the subtle effects of language become visible.
Sentiment analysis applied to backlinks
To illustrate our example, I chose to select four backlinks surrounded by content rich enough in words to make the sentiment analysis relevant. So I deliberately set aside the others, which would obviously not be possible in a web-scale model.
Our example is based on the links to the Bang and Olufsen BeoSound Shape page and is directly inspired by the Tidy Text Mining site for the application of sentiment analysis.
Preparation of the dataset
I directly put the referral domain name (Referral) and the content surrounding the backlink (Content) in an Excel file.
Loading libraries
library(readxl)
library(tidytext)
library(ggplot2)
library(reshape2)
library(wordcloud)
library(tidyverse)
library(tidytext)
library(tidyr)We load the packages we’re going to need. Please note that not all illustrations generated from these libraries will be presented in this article.
The dataset is then loaded:
bang_olufsen_beosound_shape <- read_excel("~ desktop bang_olufsen_beosound_shape.xlsx") view(bang_olufsen_beosound_shape)< pre>Putting the sentiments analysis into practice with R
First, we will divide the contents so as to isolate each term on a single line.
bang_olufsen_beosound_shape_tidy <- bang_olufsen_beosound_shape bang_olufsen_beosound_shape_tidy$content <- as. character (bang_olufsen_beosound_shape_tidy$content) bang_olufsen_beosound_shape_shape_tidy bang_olufsen_beosound_shape_tidy %>%
unnest_tokens (word, Content)
bang_olufsen_beosound_shape_tidy$linenumber <- na nrowbang_olufsen_beosound_shape_shape_tidy <- nrow (bang_olufsen_beosound_shape_tidy) bang_olufsen_beosound_shape_tidy$linenumber 1: (bang_olufsen_beosound_shape_tidy)< pre>Here, the relevance of the analysis is already hampered by expressions composed of two or more terms that deserve not to be isolated. A difficulty raised in the patent mentioned above:
Current work focuses mainly on the use of unigrams and bigrams – rather than higher-order grammar models – to capture feelings in the text. (2002) found that unigrams surprisingly exceed other characteristics in their ratings. Similarly, Dave et al. (2003) experimentally showed that trigrams and higher values did not show constant improvement. We assume that these experiments were hampered by the low volume of training dataset, and therefore were not able to demonstrate the effectiveness of high order n-grams in discernible subtleties in expressing feelings. Unfortunately, lower-order n-grams, such as unigrams and bigrams, are not able to capture dependencies in the longer term, which often leads to problems of accuracy in classification.
The sentiment associated with each term is then measured:
bing <- get_sentiments ("bing") bing_word_counts <- bang_olufsen_beosound_shape_tidy %>%
inner_join (bing) %>%
count (word, sentiment, sort = TRUE) %>%
ungroup ()We then generate a word cloud that allows us to distinguish between positive and negative terms:
bang_olufsen_beosound_shape_tidy %>%%
inner_join (bing) %>%
count (word, sentiment, sort = TRUE) %>%
acast (word ~ sentiment, value. var = "n", fill = 0) %>%
comparison. cloud (colors = c ("#0088f3","#ecd078"),
max. words = 100)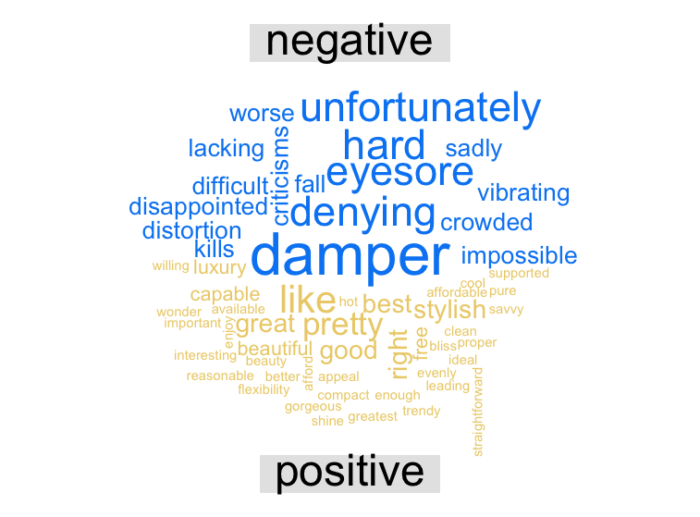
Here are a few terms that would undoubtedly deserve to appear in positive and non-negative feelings such as “distortion” and “vibrating”. We come back to the measurement of unigrams versus n-grams.
We then generate a breakdown of sentiments by referent domain:
janeaustensentiment <- bang_olufsen_beosound_shape_tidy %>%
inner_join (bing) %>%
count (Referral, index = linenumber %/% 50, sentiment) %>%)
spread (sentiment, n, fill = 0) %>%
mutate (sense = positive - negative)
ggplot (janeaustensentiment, aes (index, sentiment, fill = Referral)) +
geom_bar (stat = "identity", show. legend = FALSE) +
facet_wrap (~Referral, ncol = 2, scales = "free_x")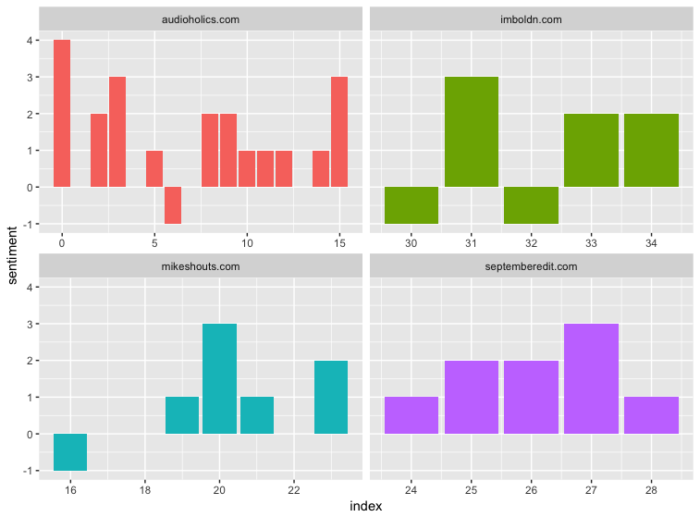
A distribution of negative and positive terms is then generated regardless of the referral domain:
bing_word_word_comptes %>%.
group_by (sentiment) %>% % >% - % de la population
top_n (10) %>%>% du haut
ungroup () %>%>% ()
muter (mutate (word = réordre (word, n)) %>%%% (ordre)
ggplot (aes (word, n, fill = sentiment) + + ggplot
geom_col (montrer la légende = FALSE) +
facet_wrap (~sentiment, balances = "free_y") +
laboratoires (y = "Sentiments",
x = NULL) +
coord_flip ()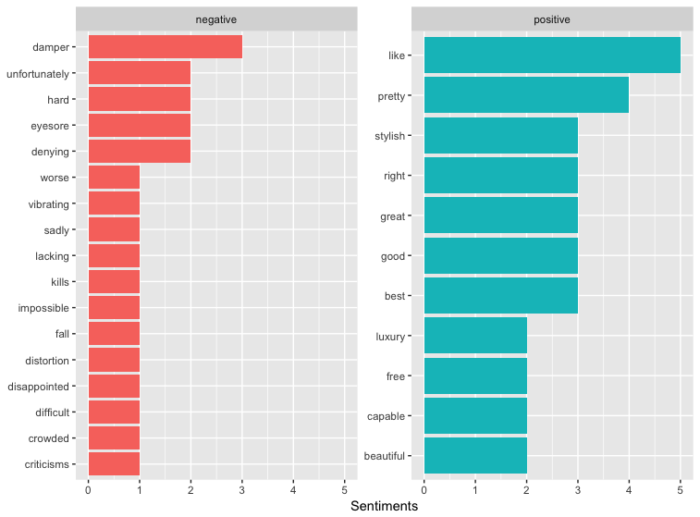
How to introduce the classification of sentiments as a measure of the quality of a backlink?
The patents “Creating a summary of feelings for local service opinions” and “Summary of feeling: Evaluation and learning of user preferences” introduce mathematical concepts to give value to positive and negative sentiment, and achieve an overall result (editor’s note: therefore per document / web page).
It is therefore conceivable that a calculation method will be decided in the future to be applied as a measure of the quality of a backlink, and thus reinforce the relevance desired by the algorithm. In this model, a negative sentiment would cause links to reverse or decrease the weight of the PageRank assigned to destination pages so that only positive links would add value. If many negative links pointed to a document, it would require many positive links of equal value to compensate for the loss of PageRank.
In 2010, Matt Cutts was answering Danny Sullivan’s questions during the SMX (Source: Search Engine Land).
Can Google know if a page is positive, negative or neutral?
Matt Cutts replied that they used the sentiment analysis but added:
I don’t think we’re using that as a ranking signal.
What's your take?



Comments ()