
Offered by Google Cloud’s Natural Language APIs, entity and sentiment analyses classify terms and extract a general feeling. Dated 2015, a Google patent entitled Rankings of search results based on entity metrics demonstrates the value of using it in our SEO actions.
Officially launched in September 2017, the Google Cloud API on Natural Language allows content to be classified easily and quickly, and sentiments to be analysed from any data source (emails, Twitter, etc.). In our case, it is the content available through the title and description tags, and the editorial content that interests us. Before introducing you to the homemade crawler (which you can obviously download to use, improve, etc.), let’s take a closer look at Google’s patent to understand how these analyses can influence our SEO actions.
Natural Language Processing
Automatic natural language processing combines linguistics, computing and, of course, artificial intelligence through the machine learning. Several research fields are dedicated to it, which are certainly not unknown to you:
- Syntax (lemmatization, etc.).
- Semantics (automatic text generation, spell checking, etc.).
- Signal processing (automatic speech recognition, etc.).
- Extraction of information (recognition of named entities, analysis of sentiments, etc.).
Classification of search results according to entities
Available on Google’s website dedicated to patents, the document on the ranking of search results in relation to entities is summarized as follows:
Computer-readable methods, systems and media are provided for classifying search results. A search system can determine several parameters based on the search results. The search system can determine weights for metrics, weights being based in part on the type of entity included in the search. The search system can determine a score by combining metrics and weights. The search system can rank the search results according to the score.
Still according to the patent, an entity is something or a concept that is singular, unique, well defined and distinguishable. In some implementations, the authors point out that the system uses four specific metrics:
- A relatedness metric,
- A notable entity metric,
- A contribution metric,
- A prize metric.
Relatedness metric
It refers to the idea that an entity is linked to another subject, a keyword or another entity. To do this, their system must learn which entities are in relation to others and what their characteristics are through co-occurrences. The authors define this process as follows:
[…] when the search query contains the reference of the entity “Empire State Building”, which is determined as being of the type “Skyscraper”, the co-occurrence of the text “Empire State Building” and “Skyscraper” in the web pages may determine the metric of the entity in question.
Notable entity metric
It refers to the importance of an entity in relation to a request or another entity. Google establishes the measure by comparing the overall popularity of the entity (number of links, social mentions, etc.) and dividing this by the value of the entity type itself.
Contribution metric
It is based on external influence points such as reviews, reputation rankings, etc. and can be weighted so that specific types of contribution measures (such as reviews) have more impact. In my opinion, the weighting is similar to the one used for rating external links.
Prize metric
It corresponds to the perceived value of a category. According to the authors:
Value measurement is based on an entity’s awards and prizes. For example, a film may have received a variety of awards such as Oscars and Golden Globes, each with a particular value. In some implementations, the price metric is weighted so that the highest values contribute most strongly to the metric.
Translate patent information into SEO actions
Although it is exciting, the reading of Google patents is always subject to our free will: is the probability or not that this search is used in the operation of the algorithm is strong? When you optimize a page (ideally from your log files), you seek to demonstrate its legitimacy towards competing pages and you naturally seek to increase its value. This is the whole point of entity analysis: how to use their classification to get as close as possible to understanding the engine. For example, entities can help optimize a website tree structure.
Building your own crawler
In order to automate the whole analysis, the construction of a homemade crawler was necessary. It retrieves the tags title, description as well as the content appearing in the body (there is unfortunately quite a lot of noise here but not all the sites being conceived in the same way, it is very difficult to isolate the editorial content only). The first part of the crawler is from the website Data Blogger. The rest of the Python code was written by Pierre, Data Scientist NLP (as well as details of the procedure described below).
Getting the crawler directory
This folder contains all the code and functions necessary for our crawler to work properly. The design of this crawler was thought to be able to automate the extraction of entities and sentiment analysis on web pages.
Description of file and script organization
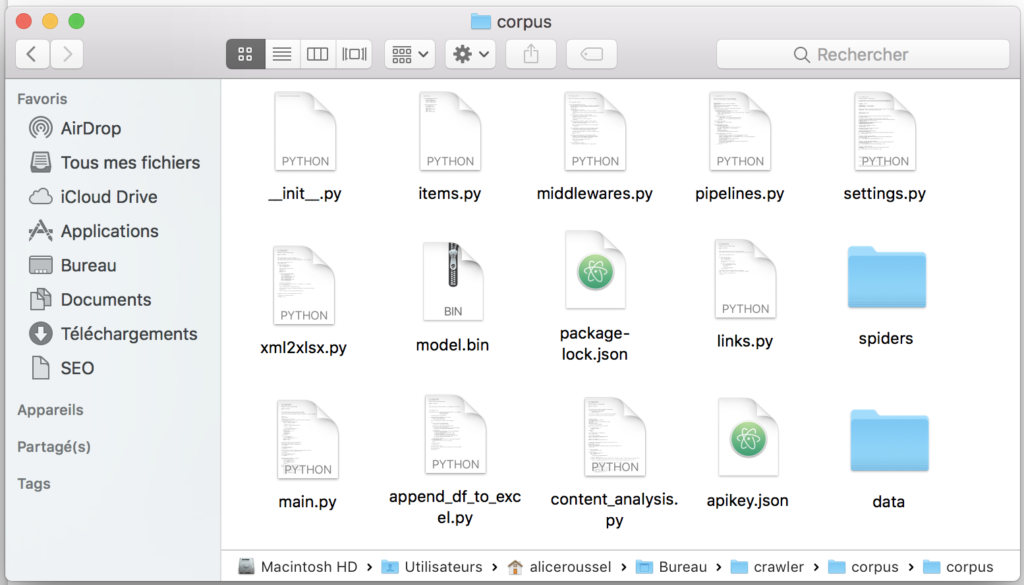
Files needed to crawl:
- __init__.py: Needed for import.
- items.py: Contains two classes that manage items.
- middlewares.py: Needed for spider creation.
- pipelines.py: Removes noise from HTML.
- settings.py: Placing the spider.
- xml2xlsx.py: Extract information from an xml file for storage in an.xlsx.
- links.py: Store in a list the internal links of the site.
- spiders/spiders.py: Both classes for spider execution.
Files needed for content analysis:
- append_df_to_excel.py: Add Dataframe content to xlsx.
- content_analysis.py: Suitable for sentiment analysis and entity extraction.
- apikey.json: Need credentials to use the natural Google cloud API (be careful, here you will need to specify your own Google Cloud identifiers).
Storing results:
- Folder data: Contains the result of the crawl in a.xlsx.
File needed to launch the application:
- main.py: Main script that performs all the necessary processing to output an.xlsx file containing the results.
Crawler operation procedure
- Download crawler archive.
- Decompress archive.
- Open the terminal and go to corpus directory.
cd crawler/corpus/corpusTo be able to use the content analysis feature, type the following commands in the terminal:
pip3 install –upgrade google-cloud-language export GOOGLE_APPLICATION_CREDENTIALS="apikey.json"If nothing happens, then everything is fine! Just go to the next step 🙂
Start the crawler with the command below:
python3 main.pyEnter the URL of the website to crawl. This must be in the form:
http[s]://[www.]example_site.[en | com | net | org]Let the program run until you get this in the terminal:
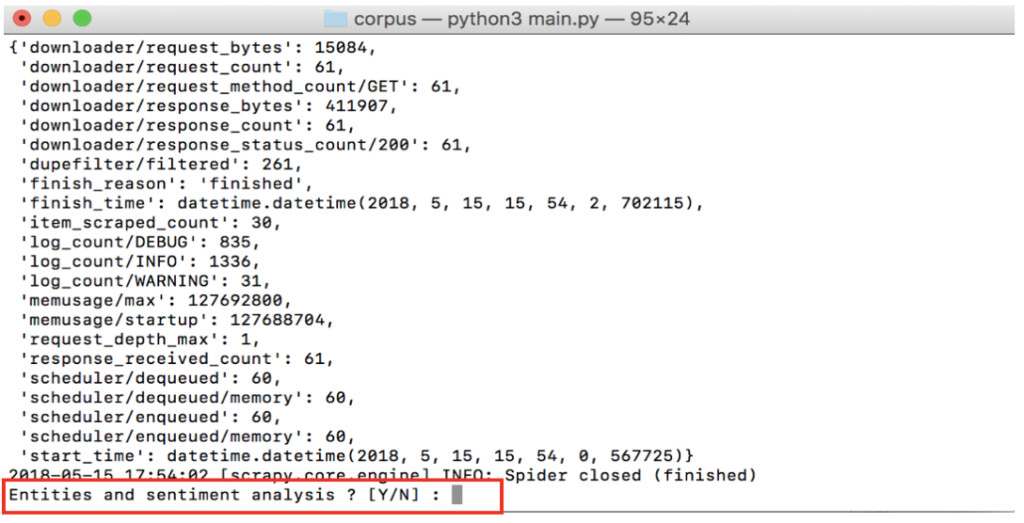
Before choosing whether or not to do a content analysis, you can check in the data folder that an.xlsx file has been created with the result of the crawl.
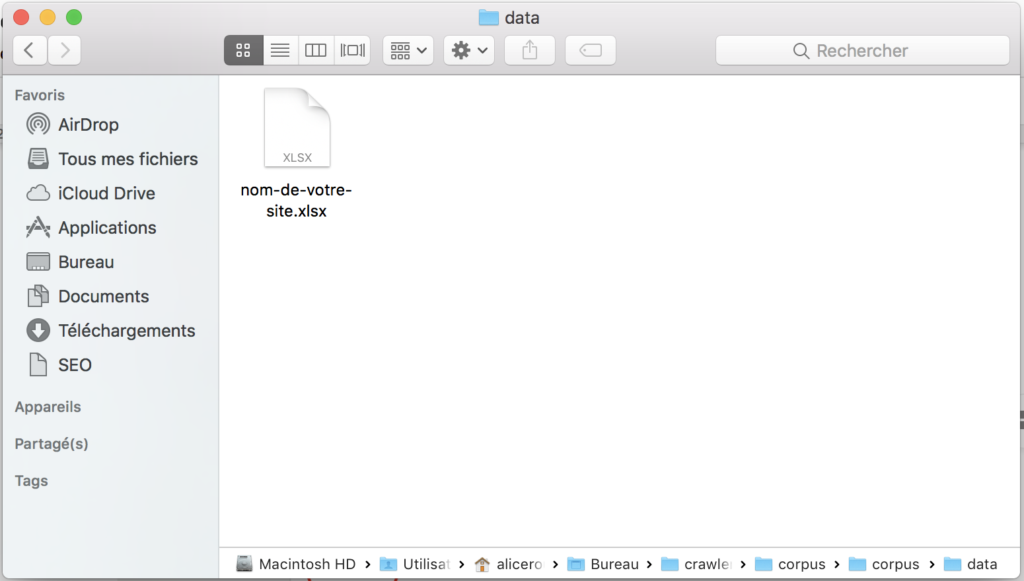
The form of the Excel file is as follows:
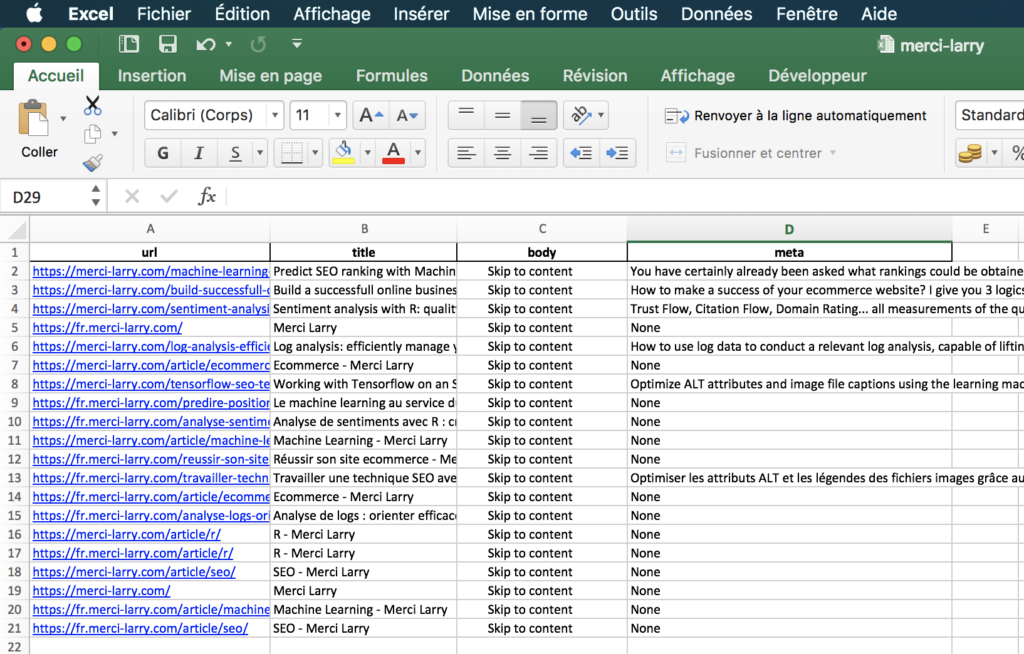
You must choose on which batch of data to perform the analysis. Once, your choice is made between ‘title’, ‘body’, ‘metadescription’, a new window should appear. You can then choose the links on which the entity analysis should be done.
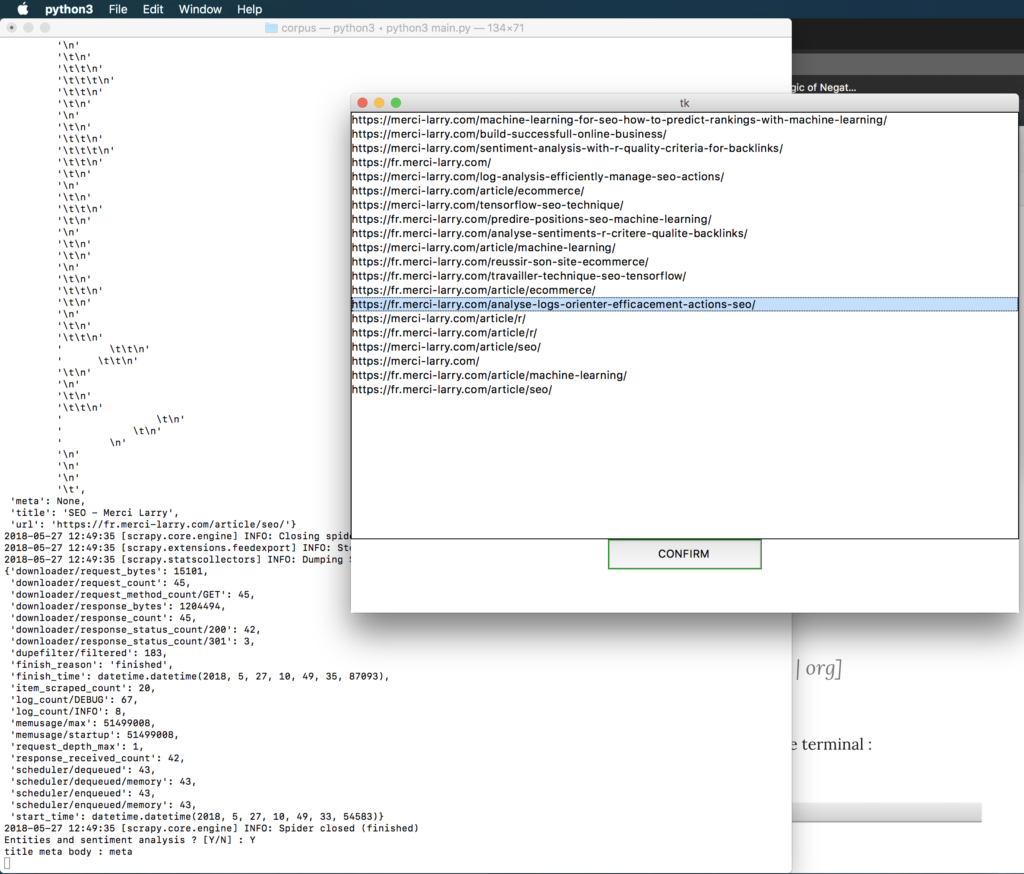
A new window opens, you must confirm again. The analysis will take more or less time depending on the number of links selected (in average it takes 1 minute). At the end of the execution the following window will appear. The entity analysis is then in the same Excel file previously created (a page analysis in a sheet).
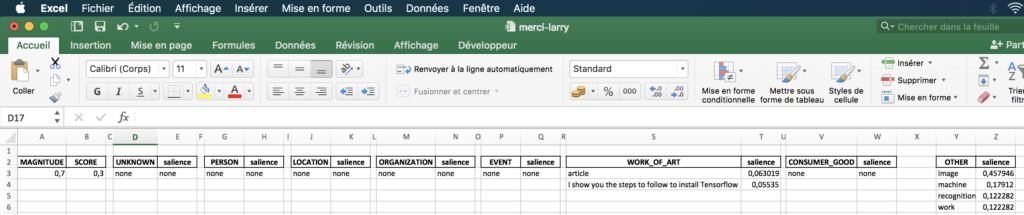
The magnitude indicates the overall strength of emotion (positive and negative) in the given text, between 0.0 and +inf. Unlike the score, the magnitude is not normalized. Each expression of emotion in the text (both positive and negative) contributes to the magnitude of the text (so longer text blocks may have larger magnitudes). The term salience refers to the importance or relevance of this entity in relation to the whole text of the document. This note can facilitate the search and summary of information by giving priority to relevant entities. Scores closer to 0.0 are less important, while scores closer to 1.0 are very important.
Now you have a good basis for your entity and sentiment analysis! 🔥



Comments ()