Buying an expired domain

First of all, let’s give some context about having bought an expired domain. At Pictarine, we aim to test a lot of things and to build MVPs to confirm or disconfirm our hypothesis. To test a new photo product and possibly new markets (in addition to the US), we spent a few hundreds of dollars on Facebook Ads to test both the product and the conversion funnel. Guess what? It worked! We sold a few products. Enough learning to start thriving for more. Below’s how an expired domain came into our discussions.
This post is the first part of a blog post series dedicated to building an MVP and demonstrating its scalability.
Part 2: Buying an expired domain: learnings on ranking capabilities
Why should I buy an expired domain?
Well, I guess there are plenty of reasons to do so. For us, it was pretty simple. We didn’t want to bother looking for a brand name, especially if the MVP demonstrates that it can’t be scalable. So I went on seo.domains and look for domain names containing our product name: Poster. I found only one domain name: Poster Collective; the perfect match actually! $350 later, we’ve got our brand name.
Things to check before buying an expired domain
- I first looked at the website on Wayback machine to see what it looked like and to see how it had evolved over the years. Before it expired; it was a “clean” art-themed site. I noted my initial findings thus: lots of images & not much content though.
- So, again, we didn’t want to capitalize on anything built in the past but just make sure that this domain wouldn’t be a problem of any sort. A site: command on Google search only showed three URLs; advertising the domain for sale.
- I then checked the backlinks on Ahrefs and they were all related to the topic, some of them still exist, despited leading to 404 pages. I also checked the anchors used years before and they were mostly (90% of them) targeting the brand. Anything spammy here, in conclusion.
- The website wasn’t ranking well for any specific keyword at the time, despite interesting search volume.
Setting up our new (expired) domain
We were granted access to the (not anymore) expired domain within 24 hours. It took us 7 days to get our website live on this domain. To first test our new photo product, it was previously live on a domain dedicated to run our tests. Mostly here, the rough idea is to spend money through social and / or search ads and see if it can work. If so, then we use a more “official” domain name.
We deployed our domain name using Google Cloud Platform for hosting and data storage, and Next JS to run our code.
Search Console: crawl stats analysis
Disclaimer: we didn’t bother looking at the server logs as the website is still quite small. Still, we only looked at them to get the full list of Googlebot hits on 404 pages (from the old website) and then manage our redirects.
The crawl report is obviously not the report we wanted to focus on but it was kinda fun to look at it; just to get some understandings about how Google was dealing with the old and new index of pages.
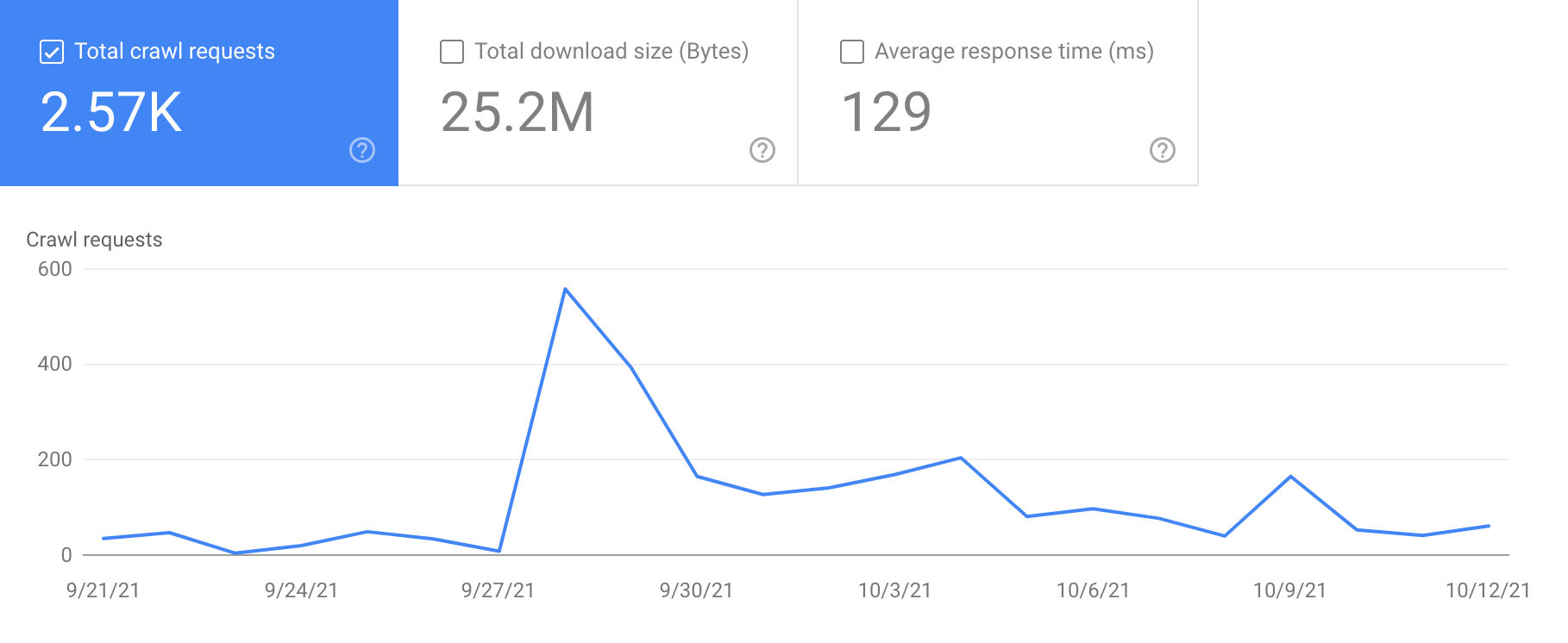
- We noticed daily hits before the site went online, which shows that Google strive to crawl expired domains (I’d be curious to know the total cost it represents!). I should add that hits were being made on lots of old pages.
- During the first 24 hours after the website went live, we saw a spike in the total number of crawl requests: the submission of the sitemap (directly in the Search Console) as well as the manual submission of a few URLs was enough to generate crawl demand.
- The following days, we noticed a more important exploration than the days preceding going live, without that being too important either.
Hosts
It helped us getting the full list of hosts being used years before in order to update our redirect list.
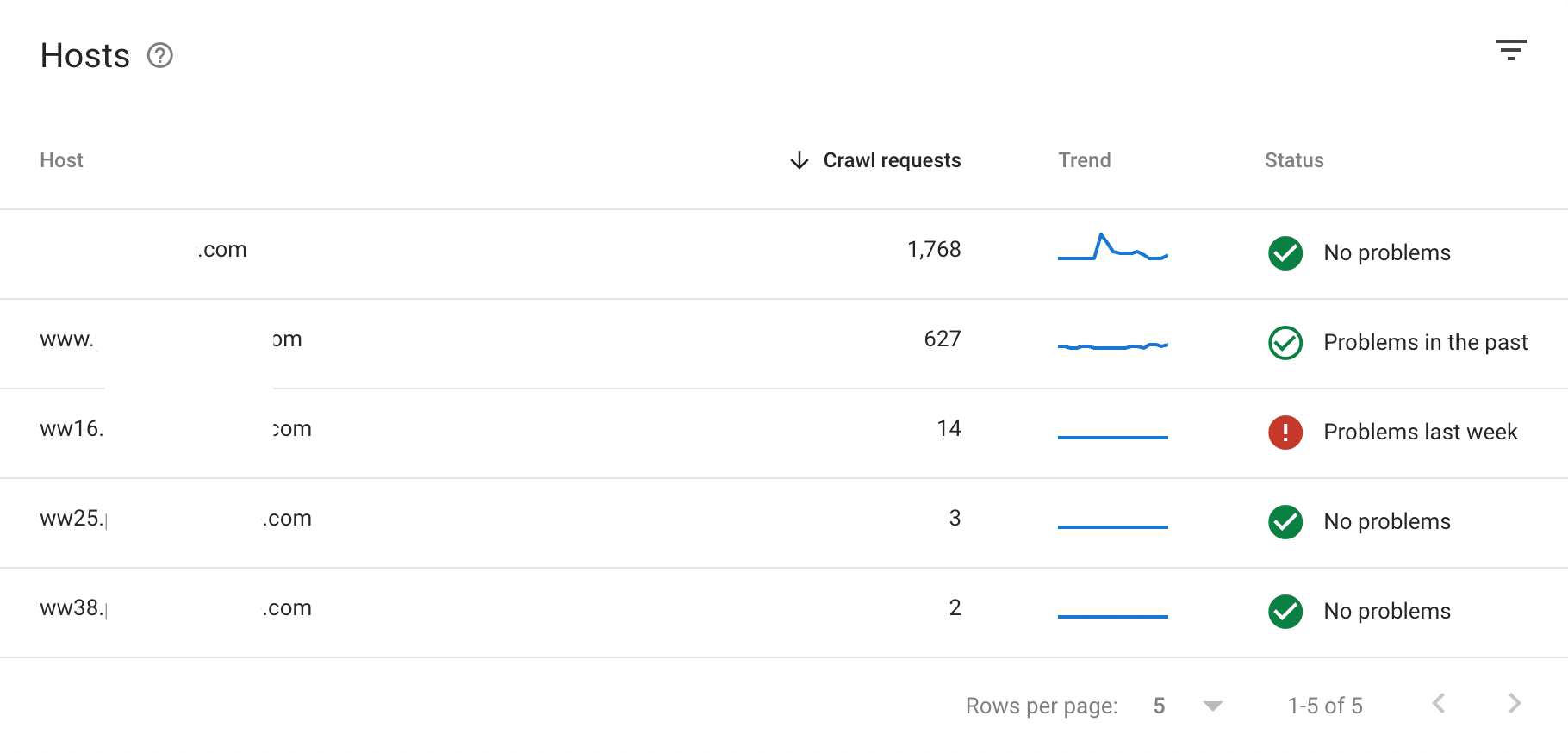
Crawl requests breakdown
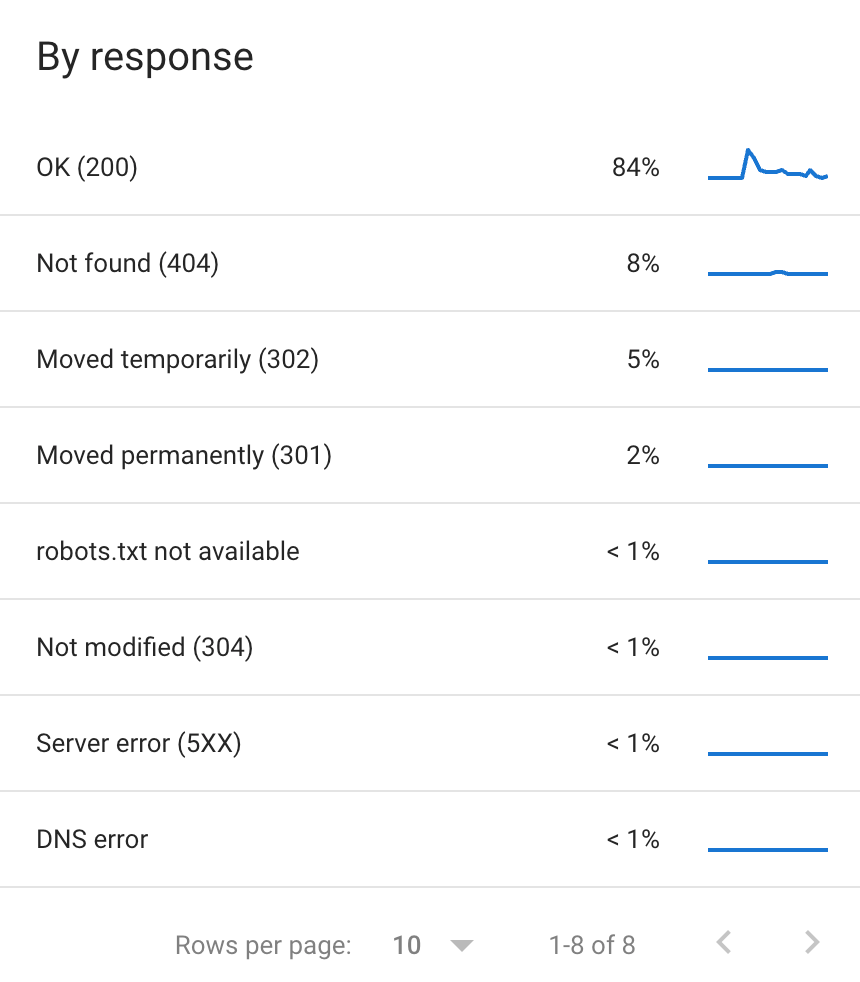
Status code
- If we break down the hits by status code, we can see that most of the time, Google explores 200 status codes.
- What is more annoying are the 302s because they indicate a temporary redirect whereas, when we look at the details, we see that these URLs come from the old site and we already know that the redirect will be permanent because we do not want to reuse these old URLs: again, another clue to properly update our redirect list.
- More surprising are the hits that deplore the robots.txt being not available. Checking it by ourselves, we’ve got a few “Service unavailable” from time to time. Still something we didn’t investigate further.
- The other status codes are too small in percentage; so I didn’t look any further than that.
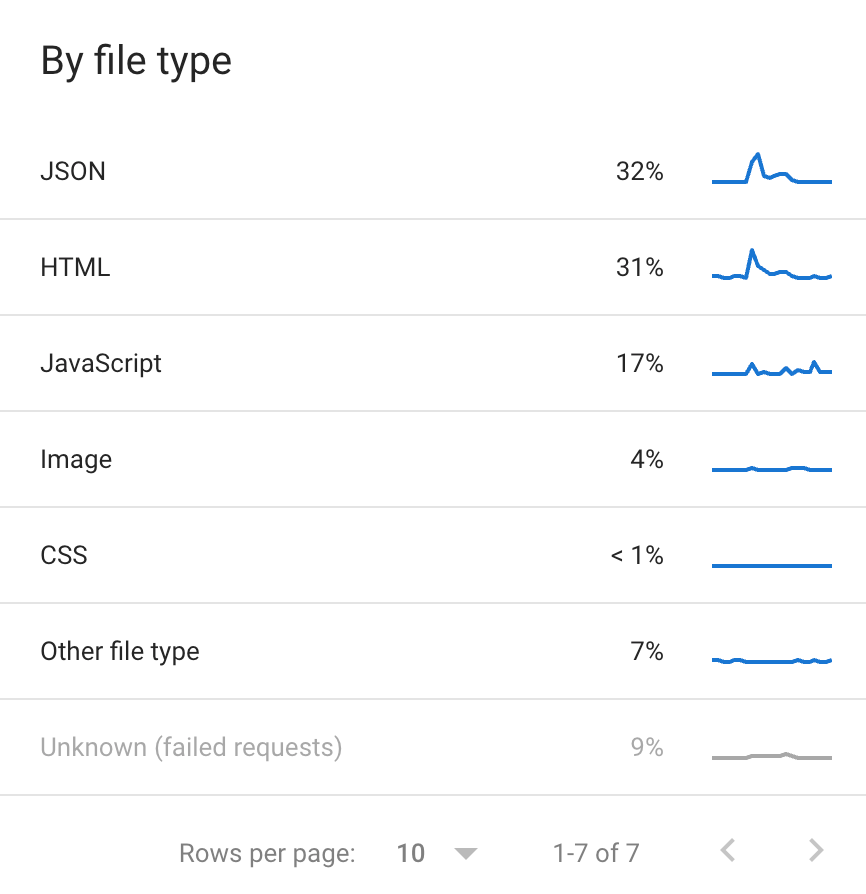
File type
I looked by file type and saw that Google crawls mostly our JSON files. At first, I thought it was the content located inside the JSON; it was the /api/ path instead.
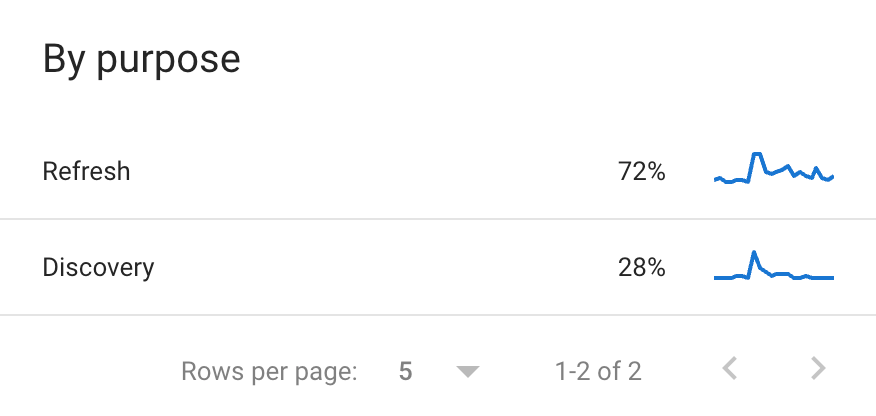
Purpose
This is definitely the hint I prefer among all the information in the crawl stats report! If we look at the type of content, we see that 72% of Google (re)crawls old content. If I go by my experience where I have seen many websites having their old pages crawled in majority. The share of discovery is 29% and took place mostly after the site was sent live. I was still a bit surprised, considering that the domain name was abandoned for almost six years.
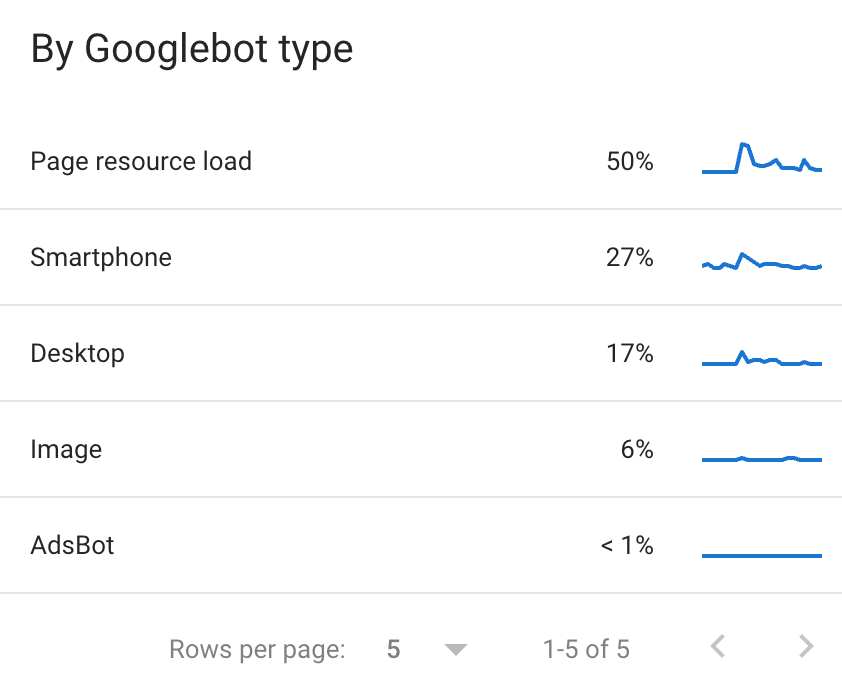
Googlebot type
Finally, if we look at the breakdown by Googlebot type, we can see that Page resource load is the majority at 50%, Google crawls mainly resources, especially those it needs to render pages. Once we will disallow the /api/ path on the robots.txt, we should significantly reduce its share.
Another area of optimisation for getting hits on value-added pages will be to return a 304 (not modified since) response code on resource pages, in order to reduce hits on resources that are not constantly updated. I find it kind of funny to spot AdsBot on the list, considering we only ran Facebook Ads at that moment.
Conclusion
Here are the very first findings and learnings after having bought an expired domain. In the next article, I will talk about working with Google Cloud Platform and using Next JS associated with a Google spreadsheet to run the code and simulate a CMS.
Feel free to share your feedback and questions if you have some!