
How I used Claude Code to turn manual and (probably) biased competitive research into structured data, and why it changes how a junior can work.
When Thomas joined the team to design our social ads, I had a classic management problem: how do you give a junior a solid methodology on a role we'd never really structured before?
We were starting from scratch on a channel we'd never really structured before: Meta Ads, with a specific focus on reaching non-intent users so basically people who aren't actively looking to print their photos, but who could be convinced to. It's a different game from search or retargeting, and Thomas was going to be the person building our creative approach from the ground up.
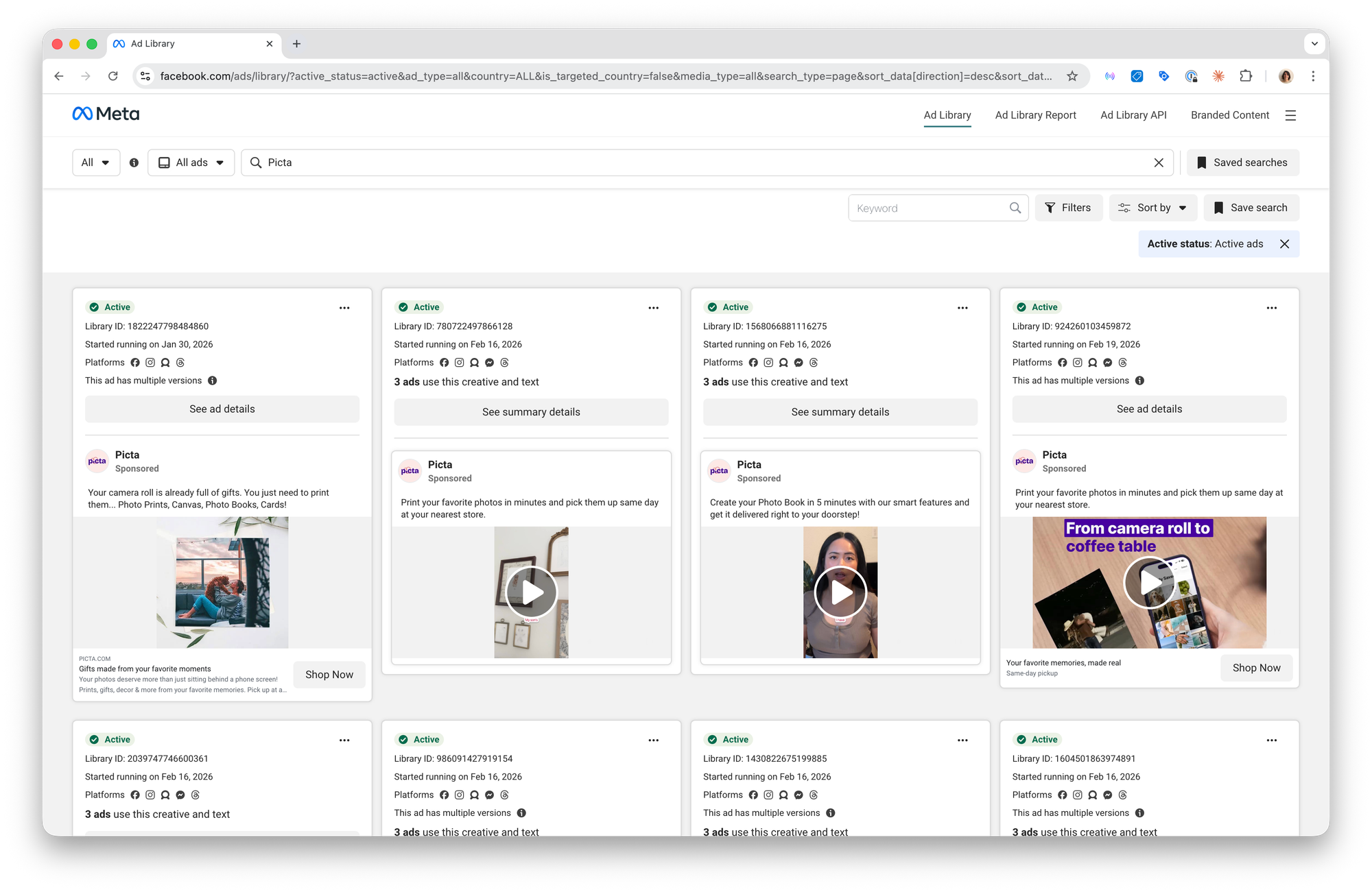
On our other marketing channels, we have years of iteration behind us such as tested frameworks, clear processes, a playbook. Here, we had none of that. And one of the things I knew we needed to get right early was competitive research. If you're trying to reach people who aren't looking for you, understanding how competitors talk to that same audience (what angles they use, what formats they push, what offers they lead with) is one of the few signals you have 🥲. We were doing it the way most teams do: a few screenshots here and there, a quick scroll through the Ad Library. Individual perception it is.
Then I came across a use case in Lenny's Newsletter about using Claude Code to scrape the Facebook Ad Library. I decided to test it. Here's what happened and why it's become one building block of how we're setting Thomas up to work.
The problem with manual competitive research
Before getting into the technical side, it's worth being specific about what we were actually trying to fix.
Thomas's job is to design ads that work. To do that well, he needs to understand what competitors are running; not just what looks good, but what's actually being pushed at scale, what messaging frameworks keep appearing, what promotional mechanics are in play, what formats are being tested. That kind of knowledge is genuinely useful.
The problem is that manual research has two built-in limitations:
- The first is time: scrolling through the Ad Library, saving screenshots, trying to spot patterns across dozens of ads is slow. It's the kind of work that gets deprioritized the moment something more urgent comes up.
- The second is bias: when one person does a quick scan, they see what catches their eye. They screenshot the ad that surprised them, the copy that felt clever, the format they hadn't seen before. What they don't capture is the full picture: the 30 variations of the same ad, the promo code appearing across 25 creatives, the competitor who launched 25 new ads in a single day.
We needed a way to get structured, quantitative data out of a process that had always been qualitative and impressionistic.
Building the workflow
I opened Claude Code for the very first time and described what I wanted in plain language: scrape the Facebook Ad Library for a given competitor, take screenshots of each ad, extract the metadata, and export everything to a CSV.
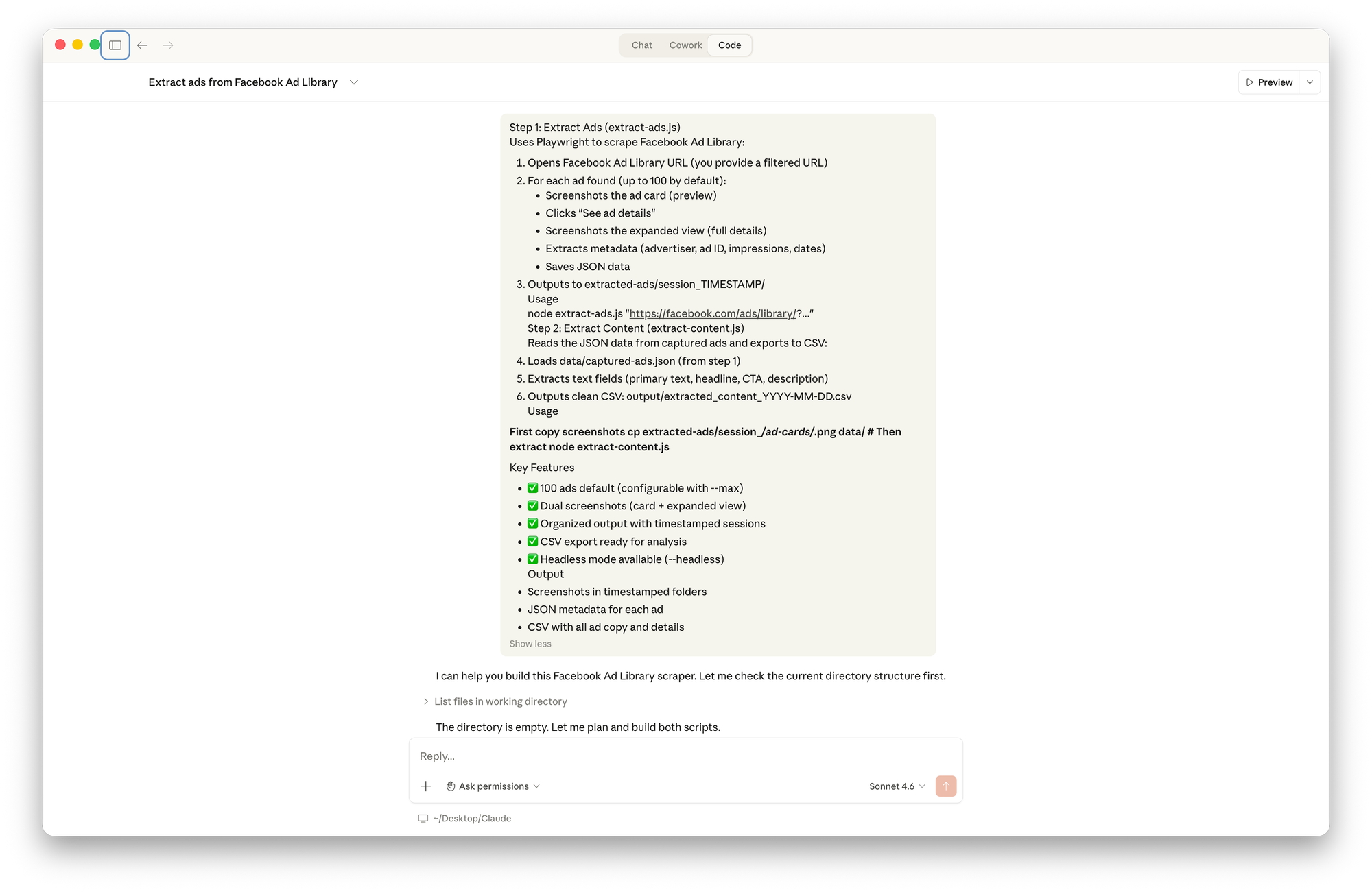
I didn't write a single line of code. Claude produced two complete scripts based entirely on that functional description.
I want to be honest about something here: I wasn't starting from zero. I've worked with data enough to understand the basic logic: scrape, extract, structure, export. Not how to code it, but what to ask for. That framing helped me describe the problem clearly.
What I couldn't have done alone is push through every obstacle without giving up. Claude Code does that back-and-forth with itself: hitting a wall, finding a workaround, testing it, correcting course. Early on, the scripts couldn't run because of a missing dependency. Claude diagnosed the environment, proposed options, and pivoted to a different approach without losing momentum. The moment where most people (including me) would have said "I'll come back to this later" (and never did, right?), that's exactly where it keeps going.
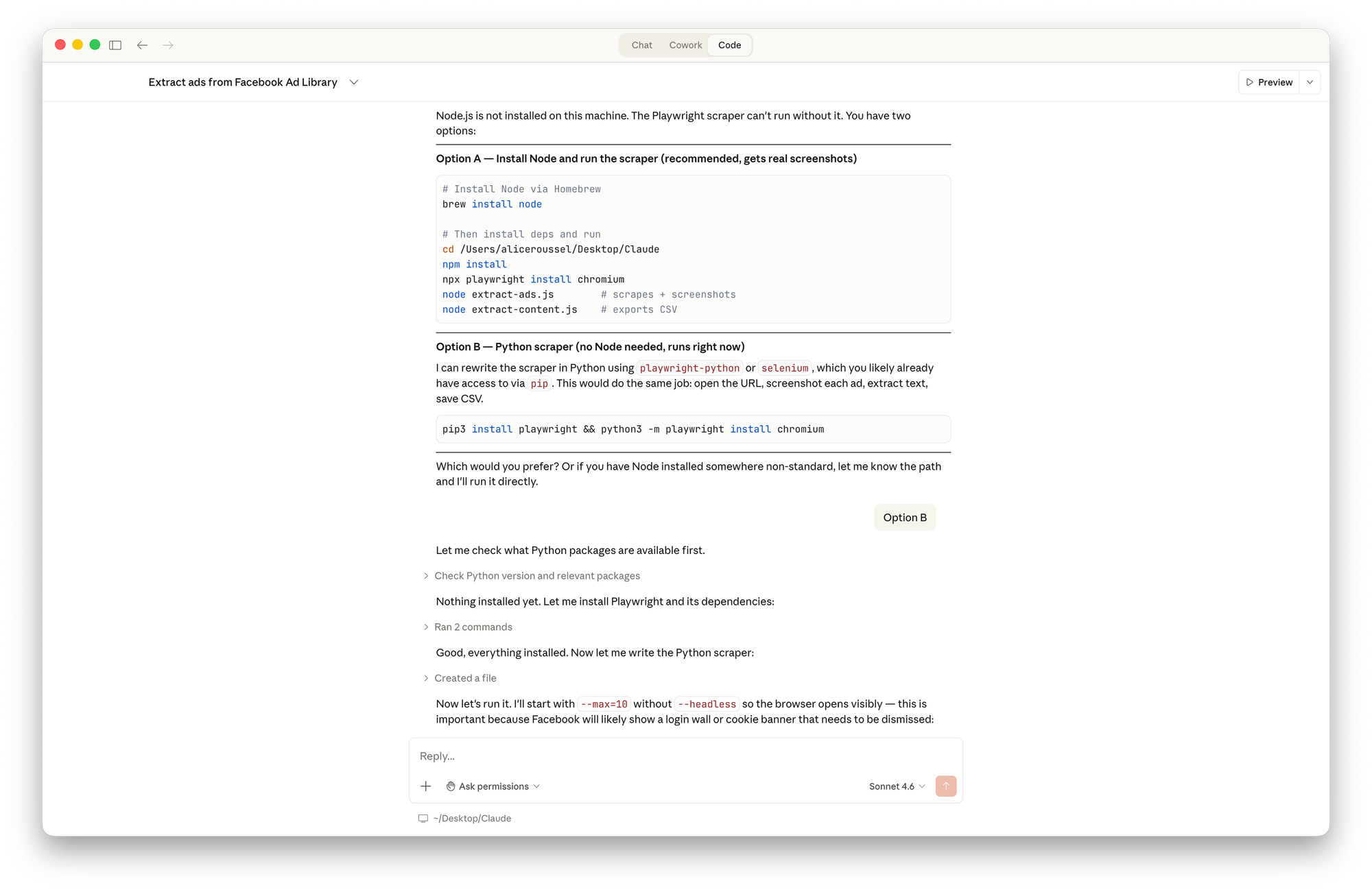
The real obstacle: extracting actual data
The first run found 10 ads and captured screenshots but every text field came back empty.
Facebook's Ad Library doesn't use stable, readable selectors. The real structure uses obfuscated, dynamically generated classes with no documentation. Instead of guessing, Claude opened a real browser on the page, inspected the live DOM, mapped every field to its precise element, and rewrote the extraction logic accordingly.
What I want to highlight is not the technical solution. It's the method: Claude didn't guess. It looked at the actual environment, identified what was really there, and wrote code that matched reality rather than assumptions.
The results
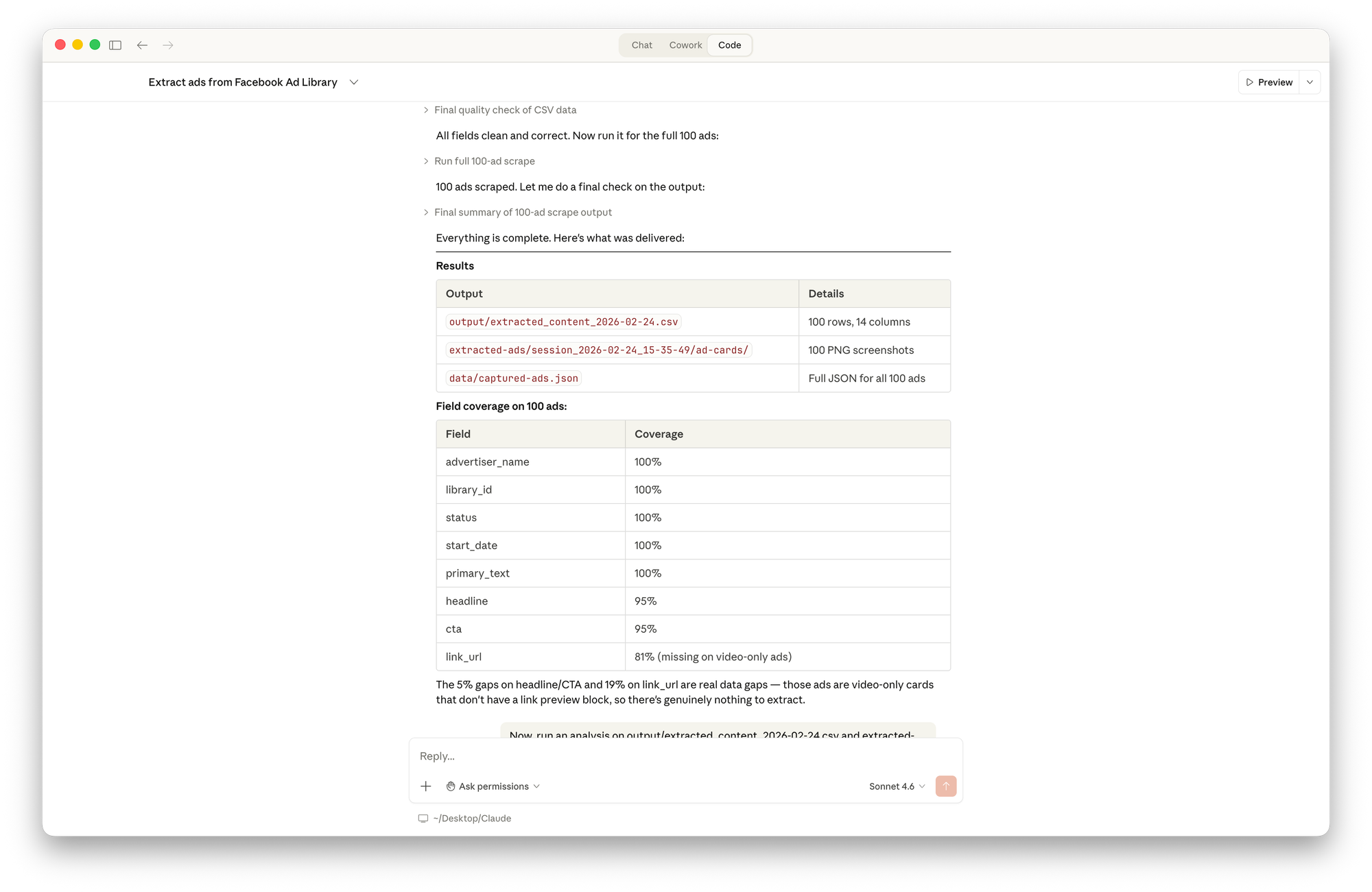
With the correct approach in place, the scraper ran cleanly on Shutterfly's Ad Library (👋): 100 ads scraped with screenshots, full coverage on advertiser, date, primary text, headline and CTA, everything exported automatically to CSV.
From there, I asked Claude to analyze the data. In minutes, it produced:
- Product category breakdown: Photo Books 31%, Gifts 29%, and so on.
- Promotional mechanics: active promo codes, offer types, discount levels.
- Copywriting signals: emoji usage 79%, ALL CAPS 100%, urgency language 34%.
- Creative deduplication: 37 unique messages across 100 ads.
- Launch timeline.
- Influencer identification: specific creator promo code appearing across multiple ads.
It also read through the 100 captured screenshots and produced a visual analysis: format mix, colour palette patterns, the consistent ad unit structure, and differences between campaign themes (Graduation, Wedding, Influencer) each with its own visual language.
For Thomas, this is directly actionable thanks to a structured breakdown of how a competitor organises their creative output across seasons and audiences.
Scaling from 1 to 4 competitors and publishing to Notion
I provided three additional Ad Library URLs, and Claude scraped all three sequentially and produced a cross-brand analysis.
The final output was a comparison of 13 levers across all four brands:
- Discount depth.
- Free product offers.
- Subscription mechanics.
- Influencer usage, social proof, and more.
- Plus a positioning map and an identification of four territories no competitor was currently occupying.
That last part, the gap analysis, is the thing that's hardest to do manually. When you're scrolling through ads one by one, you see what's there. You don't see what's missing.
Claude then fetched the schema of our existing Notion database and published the complete report directly, without me opening Notion once. Now the whole Marketing team can access and build on.

What this actually changes
Total time: roughly 1 hour to analyze 213 ads across 4 competitors, produce a structured report, and publish it to Notion. Without this approach, the same work would have taken days; assuming anyone had the bandwidth to prioritise it at all.
But the more important change isn't the time. It's what this makes possible for Thomas.
Instead of spending hours on manual research that gives him an incomplete picture filtered through his own perception, he has a repeatable process that produces quantitative and qualitative data on what competitors are actually running at scale. He can focus on the work that requires his judgment: interpreting the data, making creative decisions and testing hypotheses.
Thomas could have run Claude Code himself. He probably will, and he'll make it better. That's the point: the methodology exists now. It's his to build on.
One honest limitation
One thing it doesn't do yet, at least in how I've set it up, is run on its own. Ideally Thomas would get a fresh competitive snapshot every week without having to think about it. That's probably doable. It's just the next step I haven't taken yet.
Which is maybe the most accurate summary of what Claude Code is right now: a tool that takes you much further than you expected, faster than you thought possible and leaves you with a list of things you want to build next.


Comments ()